Como formarse en big data
Tensorflow
En las empresas de todos los sectores, la recopilación y el análisis de datos se han convertido en la prioridad número uno y los profesionales de Big Data tienen una gran demanda. IBM predice que la demanda de científicos de datos aumentará para el año 2020. Sin embargo, faltan profesionales para satisfacer la demanda. De hecho, Cisco informó que el 40% de las empresas tienen dificultades para conseguir expertos en Big Data que trabajen con ellos.
Lo cierto es que cada vez más empresas se están dando cuenta de la importancia de los científicos de datos y esto está impulsando el crecimiento del mercado. Se prevé que el mercado de big data crezca a una elevada tasa de crecimiento anual compuesta (CAGR) del 18,45%.
Una vez que hayas completado las lecciones, manejarás diferentes proyectos. Practicarás las instrucciones de la prueba de simulación en papel para prepararte para la certificación. El instructor le dará retroalimentación sobre su desempeño.
Después de la formación anterior, utilizarás CloudLab para llevar a cabo un proyecto industrial de la vida real en sectores como el de las telecomunicaciones, las redes sociales, los seguros y el comercio electrónico. Con los conocimientos adquiridos en este curso, estará preparado para realizar el examen de certificación de big data Cloudera CCA175.
Cómo manejar grandes conjuntos de datos para el aprendizaje automático
Big data, análisis de datos, ciencia de los datos… sea cual sea la dirección en la que se tome, no se puede negar que los campos tecnológicos en torno a los datos y los servicios de datos están de moda. Los datos son la moneda de la empresa, y más organizaciones que nunca están tratando de obtener algún valor de ellos.
Muchas personas con carreras tecnológicas que quieren trabajar en el campo de los datos masivos suelen volver a la escuela para obtener las credenciales adecuadas. Value Colleges, una publicación en línea que compara universidades, publicó recientemente su lista de las
El Heinz College de la Universidad Carnegie Mellon alberga la Escuela de Sistemas de Información y Gestión, donde los estudiantes pueden obtener un máster en gestión de sistemas de información con especialización en análisis de datos. La escuela también ofrece un
Uno de los pilares de Silicon Valley, no es de extrañar que Stanford esté en esta lista. La maestría en ciencias de Stanford en estadística con una concentración en big data, combinada con sus vínculos con la comunidad empresarial, hacen que sea un gran ajuste para alguien que quiera trabajar en startups. 3. Universidad de Santa Clara
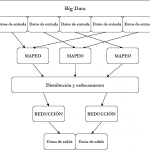
Qué son los grandes conjuntos de datos
El mundo está inundado de datos. Hay un tsunami virtual de datos moviéndose por todo el globo, renovándose a diario. Tomemos sólo los mercados financieros mundiales. Generan enormes cantidades de datos: precios de las acciones, de las materias primas, de los índices, de las opciones y de los futuros, por nombrar sólo algunos.
Pero los datos no sirven de nada si no hay personas capaces de recogerlos, cotejarlos, analizarlos y aplicarlos en beneficio de la sociedad. Todos los datos generados por los mercados financieros mundiales se utilizan para la gestión de activos y patrimonios, y deben ser analizados y comprendidos adecuadamente para que sirvan de base para la toma de decisiones. Ahí es donde entra la ciencia de los datos.
El objetivo principal de la ciencia de datos es extraer información de los datos en diversas formas, tanto estructuradas como no estructuradas. Se trata de un campo multidisciplinar en el que intervienen desde las matemáticas aplicadas a la estadística y la inteligencia artificial hasta el aprendizaje automático. Y está creciendo. Esto se debe a los avances en la tecnología informática y la velocidad de procesamiento, el coste relativamente bajo de almacenar datos y la disponibilidad masiva de datos procedentes de Internet y otras fuentes, como los mercados financieros mundiales.
Técnicas progresivas de carga de datos
En la escuela/universidad solemos pasar muchas más pruebas de unidad/exámenes trimestrales/exámenes de revisión/pruebas sorpresa, etc. Aquí hemos sido entrenados en varias combinaciones de preguntas, mezclar y combinar patrones.
Espero que todos ustedes se encuentren con estas situaciones muchas veces en sus estudios. No hay un conjunto de datos excepcional que vayamos a utilizar en Data Science. Todo porque necesitamos construir un modelo muy sólido antes de entrar a desplegar el modelo en un entorno de producción.
Del mismo modo, en el ámbito de la Ciencia de Datos, el modelo ha sido entrenado por los datos de la muestra y hace que predigan los valores con el conjunto de datos disponibles después de la lucha contra los datos, la limpieza, y el proceso de EDA, antes de desplegar en el entorno de producción, antes de que el modelo se encuentra con los datos en tiempo real/streaming.
Aquí debemos cuidar el conjunto de datos y debe coincidir con la alimentación de datos en tiempo real/streaming (para alinearse con todas las combinaciones), mientras el modelo se desempeña en un entorno de producción. Por lo tanto, la elección del conjunto de datos (preparación de datos) es realmente clave antes del proceso de T&T. De lo contrario, la situación del modelo se vuelve patética… como en la imagen de abajo. Podría haber una gran pérdida de esfuerzo, un impacto en el coste del proyecto y terminar con un servicio al cliente insatisfecho.