Impala big data
índices impala
La explosión de datos de la última década no ha decepcionado ni un ápice a los entusiastas del big data. Ha planteado una serie de retos y ha creado nuevas industrias que requieren continuas mejoras e innovaciones en la forma de aprovechar la tecnología.
El Big Data sigue creciendo. Sigue presionando a las plataformas de consulta, procesamiento y análisis de datos existentes para que mejoren sus capacidades sin comprometer la calidad y la velocidad. Se han hecho varias comparaciones y a menudo presentan resultados contrastados. Cloudera Impala y Apache Hive son dos competidores feroces que compiten por la aceptación en el espacio de las consultas de bases de datos. Mientras que Hadoop ha surgido claramente como la herramienta de almacenamiento de datos favorita, el debate Cloudera Impala vs Hive se niega a establecerse.
Intentamos profundizar en las capacidades de Impala , Hive para ver si hay un claro ganador o son estos dos campeones por derecho propio en diferentes terrenos. Comenzamos pinchando cada uno de ellos por separado antes de entrar en una comparación cara a cara.
Impala big data en línea
Impala big data 2022
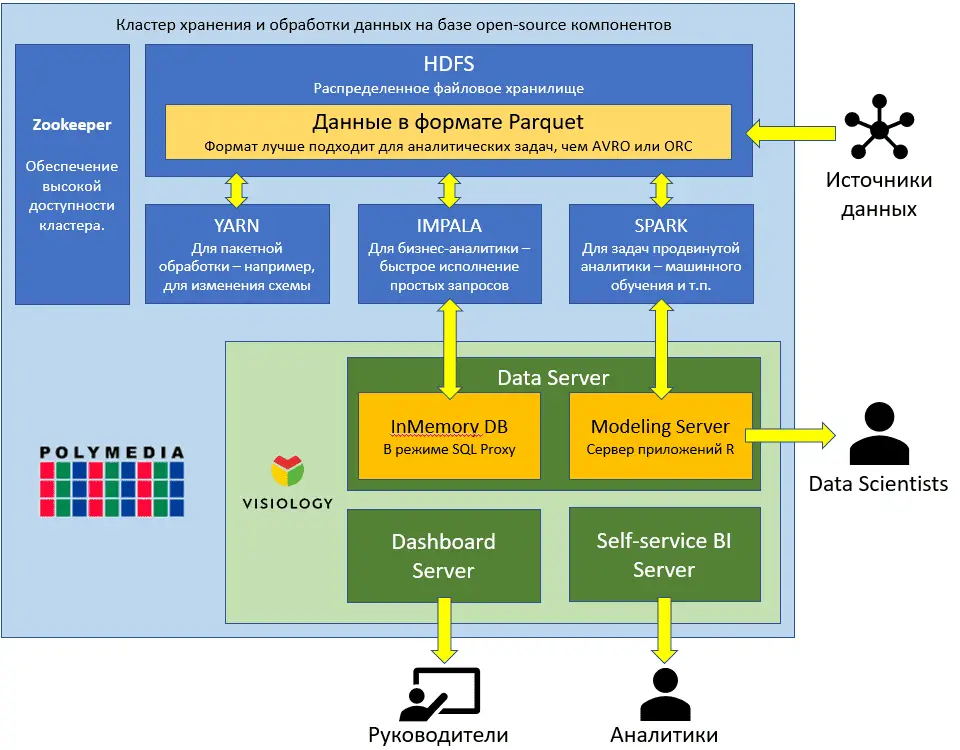
Impala es un motor de consulta SQL MPP (Massive Parallel Processing) para procesar grandes volúmenes de datos almacenados en el clúster Hadoop. Es un software de código abierto escrito en C++ y Java. Proporciona un alto rendimiento y una baja latencia en comparación con otros motores SQL para Hadoop.
Impala combina el soporte SQL y el rendimiento multiusuario de una base de datos analítica tradicional con la escalabilidad y flexibilidad de Apache Hadoop, utilizando componentes estándar como HDFS, HBase, Metastore, YARN y Sentry.
A diferencia de Apache Hive, Impala no se basa en algoritmos MapReduce. Implementa una arquitectura distribuida basada en procesos daemon que se encargan de todos los aspectos de la ejecución de consultas que se ejecutan en las mismas máquinas.
Aunque Cloudera Impala utiliza el mismo lenguaje de consulta, el mismo metastore y la misma interfaz de usuario que Hive, difiere de Hive y HBase en ciertos aspectos. La siguiente tabla presenta un análisis comparativo entre HBase, Hive e Impala.
Impala big data online
Consiga un aumento del rendimiento de un orden de magnitud en comparación con las alternativas para la única solución analítica interactiva real nativa de Hadoop. Construido como un motor de procesamiento paralelo masivo (MPP), Impala puede soportar cargas de trabajo de alta concurrencia para proporcionar un amplio acceso a los analistas de negocios a través de todo el negocio, para el tiempo más rápido a los conocimientos.
Interactúe con Impala utilizando las habilidades y herramientas más conocidas para garantizar una fácil adopción por parte de todos los usuarios. Con la compatibilidad con ANSI SQL, puede minimizar cualquier interrupción del negocio, ya que los usuarios pueden ejecutar cargas de trabajo SQL nuevas y existentes utilizando el lenguaje que ya conocen.
Impala es un proyecto de código abierto con licencia de Apache y, con millones de descargas, es un estándar ampliamente adoptado en todo el ecosistema. Únase a la comunidad para ver cómo otros utilizan Impala, obtener ayuda o incluso contribuir a Impala.

