Cluster big data
Instalación del clúster de big data de sql server 2019
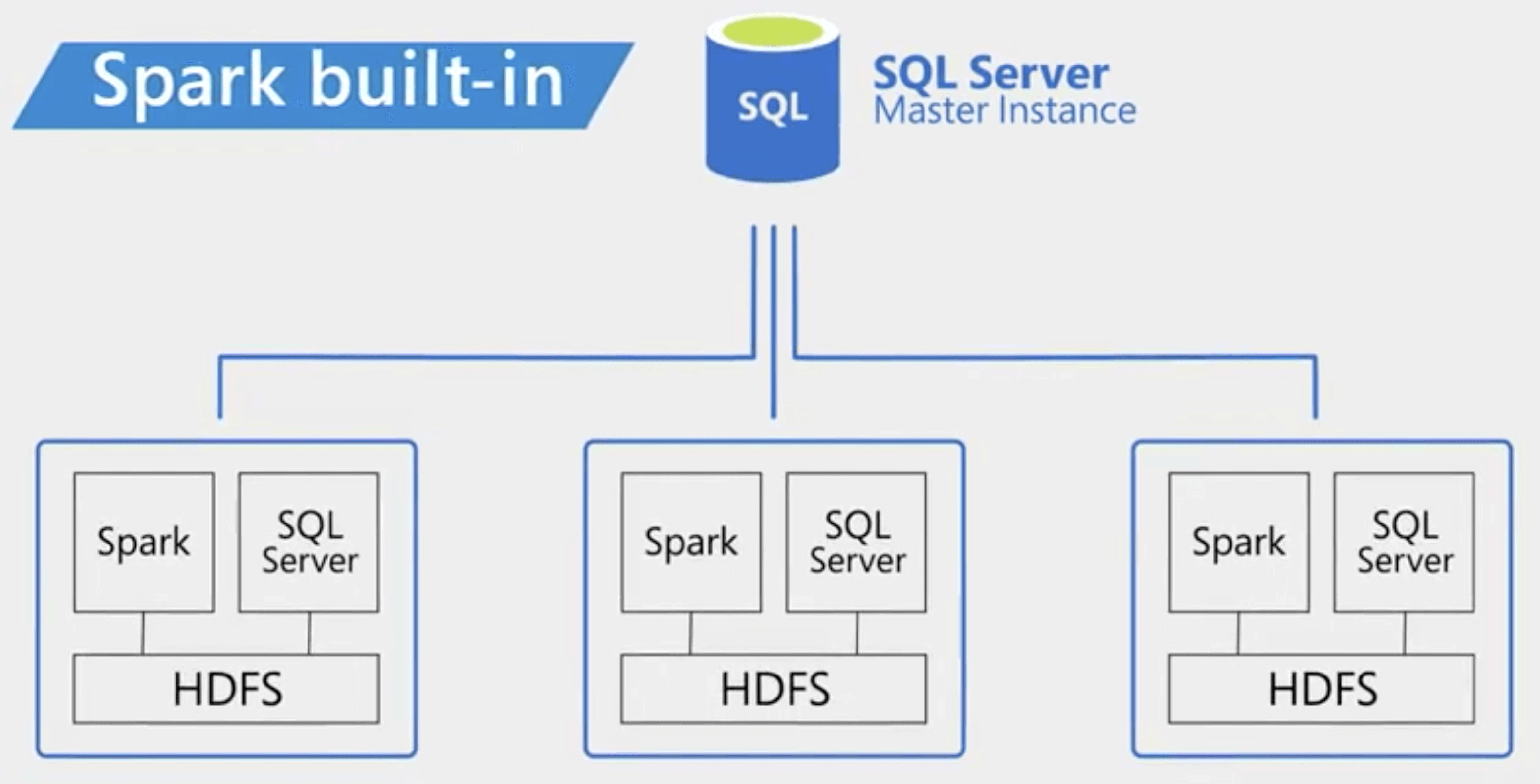
Cuando SQL Server 2017 añadió compatibilidad con Linux, se sentaron las bases para integrar SQL Server con Spark, HDFS y otras herramientas de big data que suelen estar basadas en Linux. Los clústeres de Big Data en SQL Server 2019 ofrecen estas posibilidades de integración y permiten combinar y analizar fácilmente tanto los datos relacionales como el big data.
Big Data Clusters aprovecha las mejoras de PolyBase en SQL Server 2019 para permitir la virtualización de datos de una amplia variedad de fuentes a través de tablas externas. Las tablas externas permiten que los datos que no se encuentran físicamente en la instancia local de SQL Server se consulten como si lo estuvieran, e incluso que se unan a las tablas locales para producir conjuntos de resultados sin fisuras. Se puede acceder a los datos de instancias remotas de SQL Server, Azure SQL Database, Azure Cosmos DB, MySQL, PostgreSQL, MongoDB, Oracle y muchas otras fuentes a través de las tablas externas de PolyBase. En una BDC, el motor de SQL Server también cuenta con soporte incorporado para HDFS, y puede unir todos estos conjuntos de datos, lo que permite una fácil integración de datos relacionales y no relacionales.
Servidor sql de clústeres de big data
Apache Hadoop es un marco de software de código abierto, basado en Java, y un motor de procesamiento de datos en paralelo. Permite dividir las tareas de procesamiento de análisis de big data en tareas más pequeñas que pueden realizarse en paralelo utilizando un algoritmo (como el algoritmo MapReduce), y distribuyéndolas en un clúster Hadoop.
Un clúster Hadoop es un conjunto de ordenadores, conocidos como nodos, que se conectan en red para realizar este tipo de cálculos paralelos sobre conjuntos de big data. A diferencia de otros clusters informáticos, los clusters Hadoop están diseñados específicamente para almacenar y analizar cantidades masivas de datos estructurados y no estructurados en un entorno informático distribuido. Otra característica que distingue a los ecosistemas Hadoop de otros clusters informáticos es su estructura y arquitectura únicas. Los clusters Hadoop consisten en una red de nodos maestros y esclavos conectados que utilizan hardware básico de alta disponibilidad y bajo coste. La capacidad de escalar linealmente y de añadir o quitar nodos con rapidez en función de las necesidades de volumen los hace muy adecuados para los trabajos de análisis de big data con conjuntos de datos de tamaño muy variable.
Clúster de big data financiero
Uno de los mayores retos a los que se enfrentan las empresas es cómo integrar fuentes de datos dispares procedentes de muchas fuentes diferentes, y cómo convertir los datos valiosos en información procesable. Los clústeres de big data (BDC) son la elección correcta para las soluciones de análisis de big data.
Para los clientes críticos con la seguridad que necesitan un entorno privado, la implementación de BDC con un clúster privado AKS es una buena forma de restringir el uso de direcciones IP públicas. Además, puede utilizar UDR (rutas definidas por el usuario) para restringir el tráfico de salida. Puede hacer esto con scripts de automatización que están disponibles en el repo de Github de SQL Sample – private-aks.
Puede utilizar deploy-private-aks.sh para aprovisionar un clúster AKS privado con un punto final privado, y para limitar el uso de direcciones públicas así como el tráfico de salida, utilice deploy-private-aks-udr.sh para desplegar BDC con un clúster AKS privado y limitar el tráfico de salida con UDR (rutas definidas por el usuario).
Después de desplegar un clúster AKS privado, es necesario acceder a una VM para conectarse al clúster AKS. Hay múltiples formas de ayudarle a gestionar su cluster privado AKS, y puede encontrarlas en este enlace. Aquí estamos utilizando la opción más fácil, que es aprovisionar una VM de gestión que instala todas las herramientas de big data de SQL Server 2019 requeridas y reside en la misma VNET con su clúster privado AKS, luego se conecta a esa VM para que pueda obtener acceso al clúster privado AKS de la siguiente manera :
Clúster de big data de sql server 2019 on premise
A partir de SQL Server 2019 (15.x), los clústeres de big data de SQL Server le permiten implementar clústeres escalables de contenedores de SQL Server, Spark y HDFS que se ejecutan en Kubernetes. Estos componentes se ejecutan uno al lado del otro para permitirle leer, escribir y procesar big data desde Transact-SQL o Spark, lo que le permite combinar y analizar fácilmente sus datos relacionales de alto valor con big data de gran volumen.
El controlador proporciona la gestión y la seguridad del clúster. Contiene el servicio de control, el almacén de configuración y otros servicios a nivel de clúster como Kibana, Grafana y Elastic Search.
El grupo de computación proporciona recursos informáticos al clúster. Contiene nodos que ejecutan SQL Server en pods de Linux. Los pods del grupo de computación se dividen en instancias de SQL Compute para tareas de procesamiento específicas.
Los clústeres de Big Data de SQL Server proporcionan flexibilidad en la forma de interactuar con sus big data. Puede consultar fuentes de datos externas, almacenar big data en HDFS gestionado por SQL Server o consultar datos de varias fuentes de datos externas a través del clúster. A continuación, puede utilizar los datos para la IA, el aprendizaje automático y otras tareas de análisis.

